
Reading Notes for vLLM
This is the reading note for the Efficient Memory Management for Large Language Model Serving with PagedAttention. vLLM is one of the most popular open-source inference serving systems nowadays. Basically, there are two mainstream inference serving systems: one is vLLM, and the other is SGLang.
Summary
Abstract & Introduction & Background
This is a paper about the vLLM, a serving system for inference. The most important idea they propose is PagedAttention. vLLM with the PagedAttention " achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage."
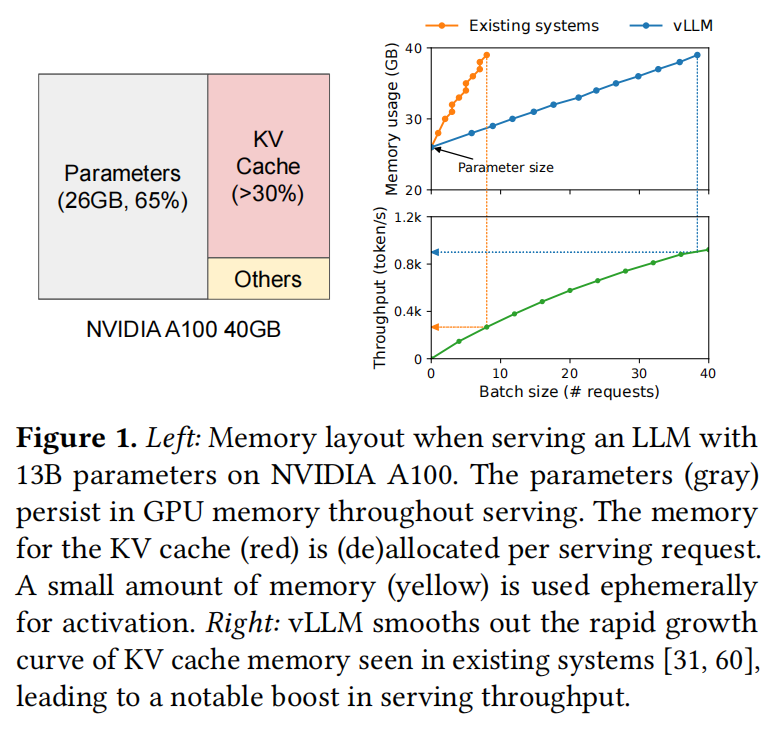
In inference, we use a lot of memory to store keys and values since we’ll repeatedly use them in our iterations.
However, the previous algorithms waste a lot of memory.
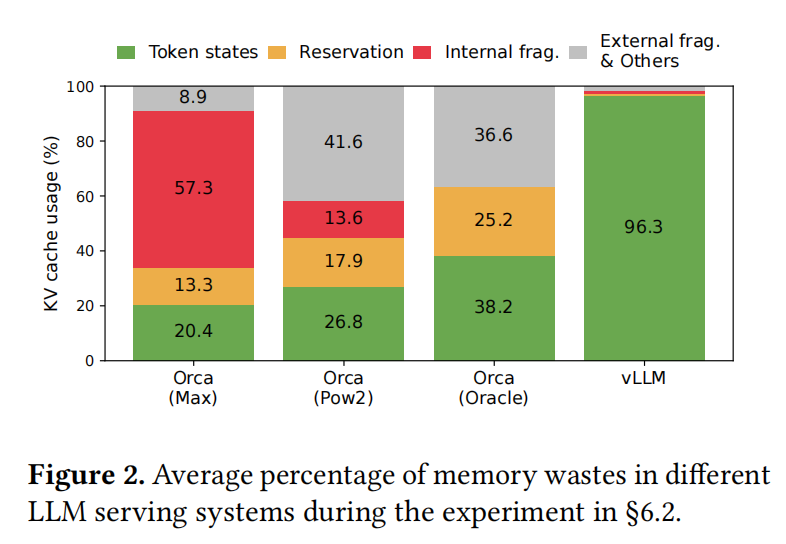
Authors use PagedAttention to solve these limitations.
The background does not have too much to summarize, just a summary of the transformer model and the limitation of the current memory management strategy.
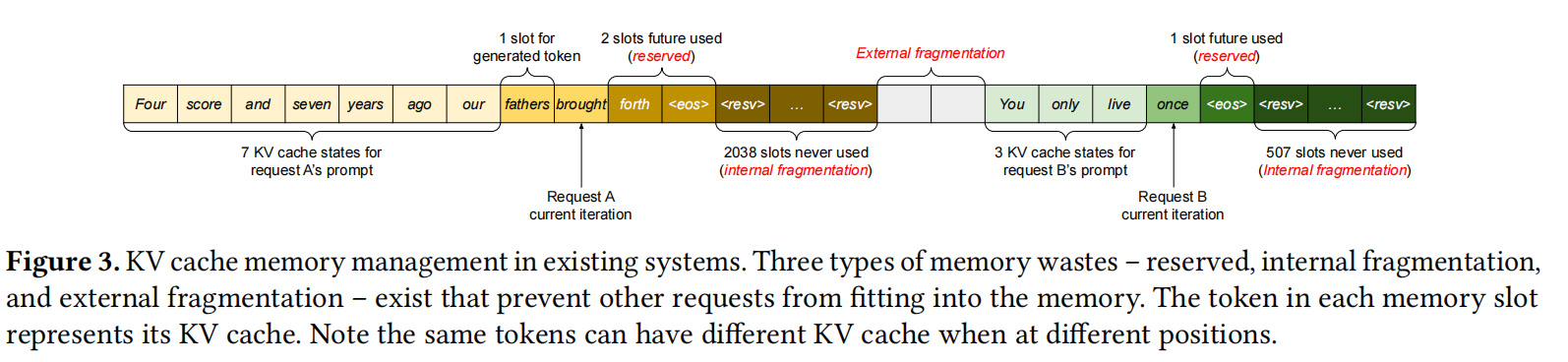
Figure 3 clearly shows why the reservation and the fragmentation waste too much memory.
Method
The main idea of the PagedAttention is just like the virtual memory of the current OS.
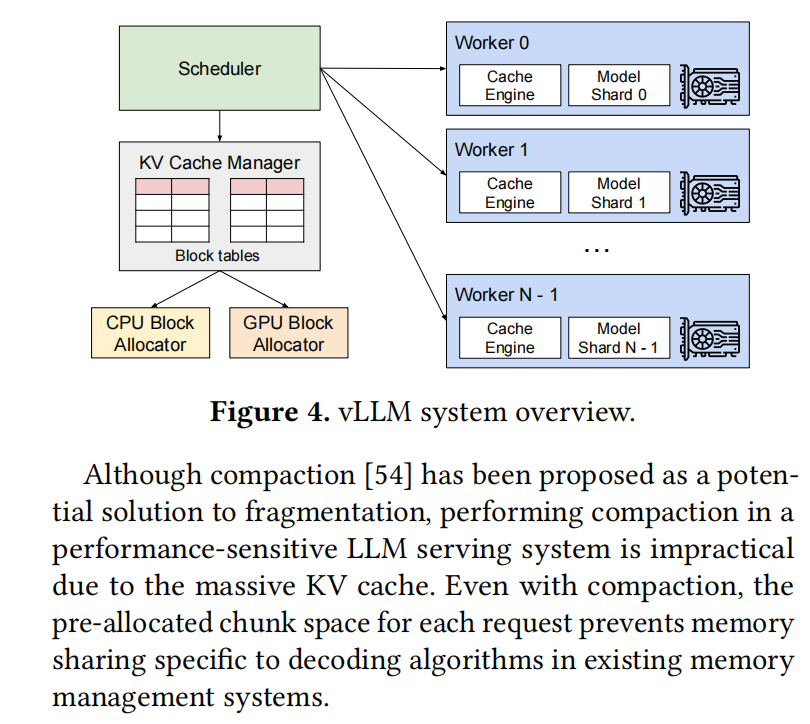
For every query, the query just thinks the corresponding K/V is contiguous, and actually, we maintain a sheet to record the actual location of each fragment of the K/V.
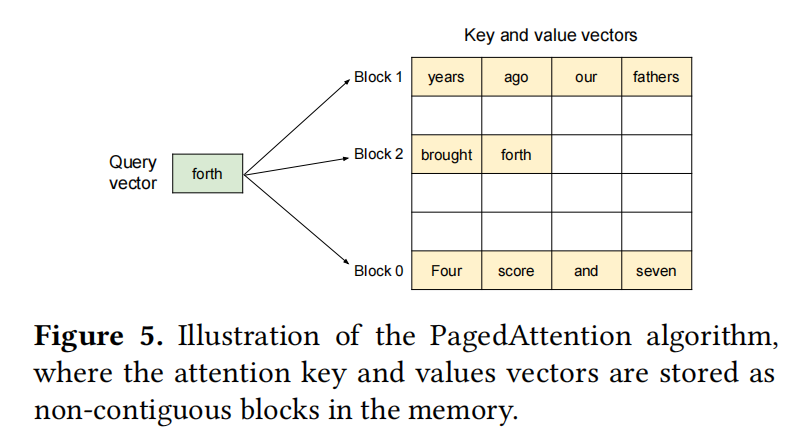
Figure 5 shows how the K/V can be managed.
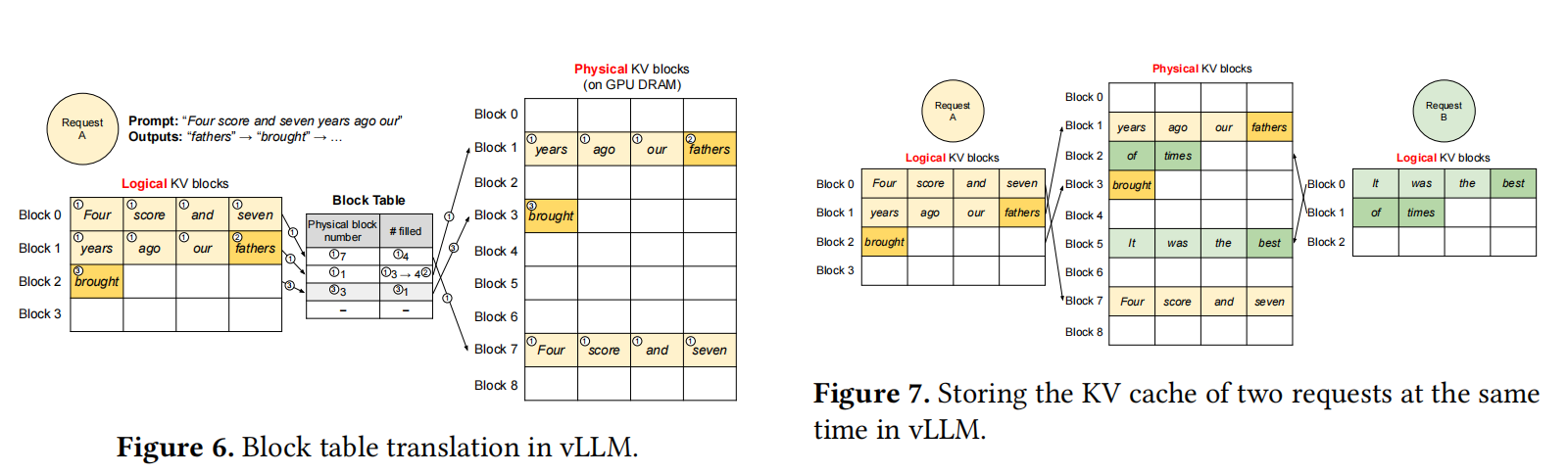
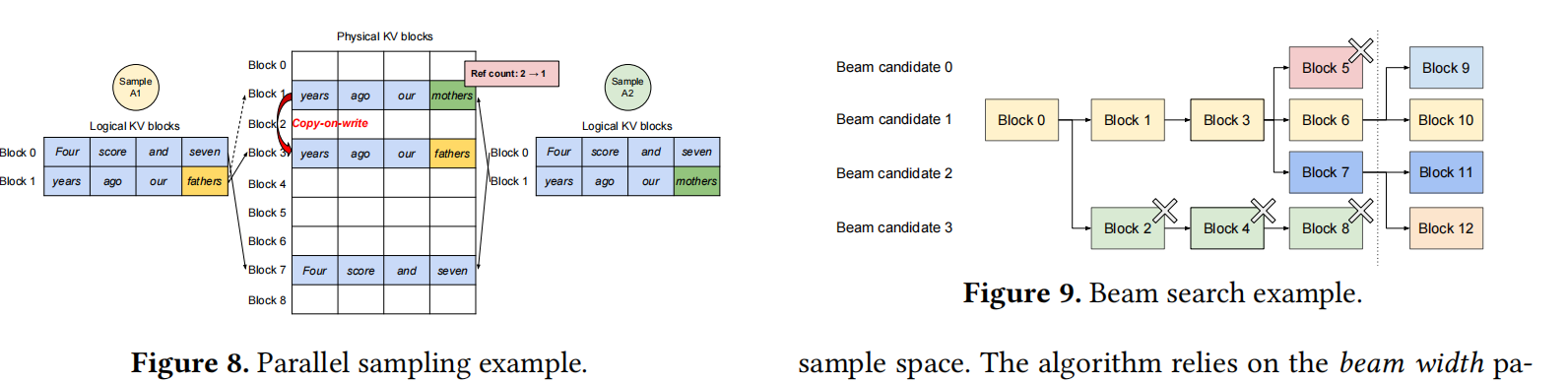
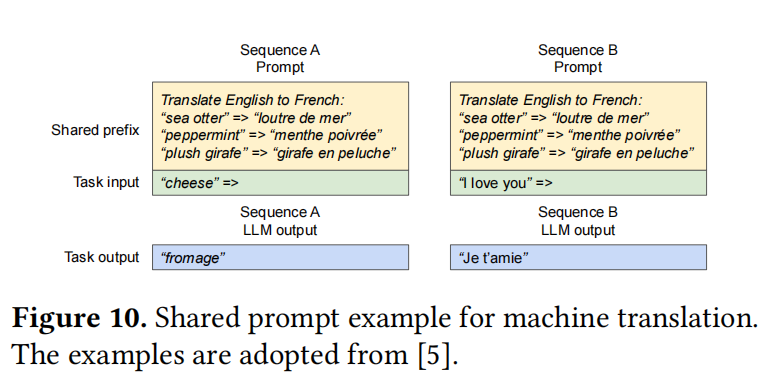
Figure 6, 7, 8, 9, and 10 tell us some details of PagedAttention. I think these figures are clear enough.
Also, a key challenge in serving Large Language Models is that as the outputs grow with each iteration, the system can run out of GPU’s physical blocks to store the newly generated KV cache. To address this, vLLM considers two main techniques to recover the KV cache for preempted requests:
- Swapping
- Recomputation
In the end, they talk a little about the distributed training.
Implementation & Evaluation & Ablation Studies
For the implementation, I think there are three techniques we should pay attention to:
- Fused reshape and block write
- Fusing block read and attention
- Fused block copy
They also mention that they create many methods that should be enough for future development.
The evaluation part do not have too much to talk about, I just put their figure here:
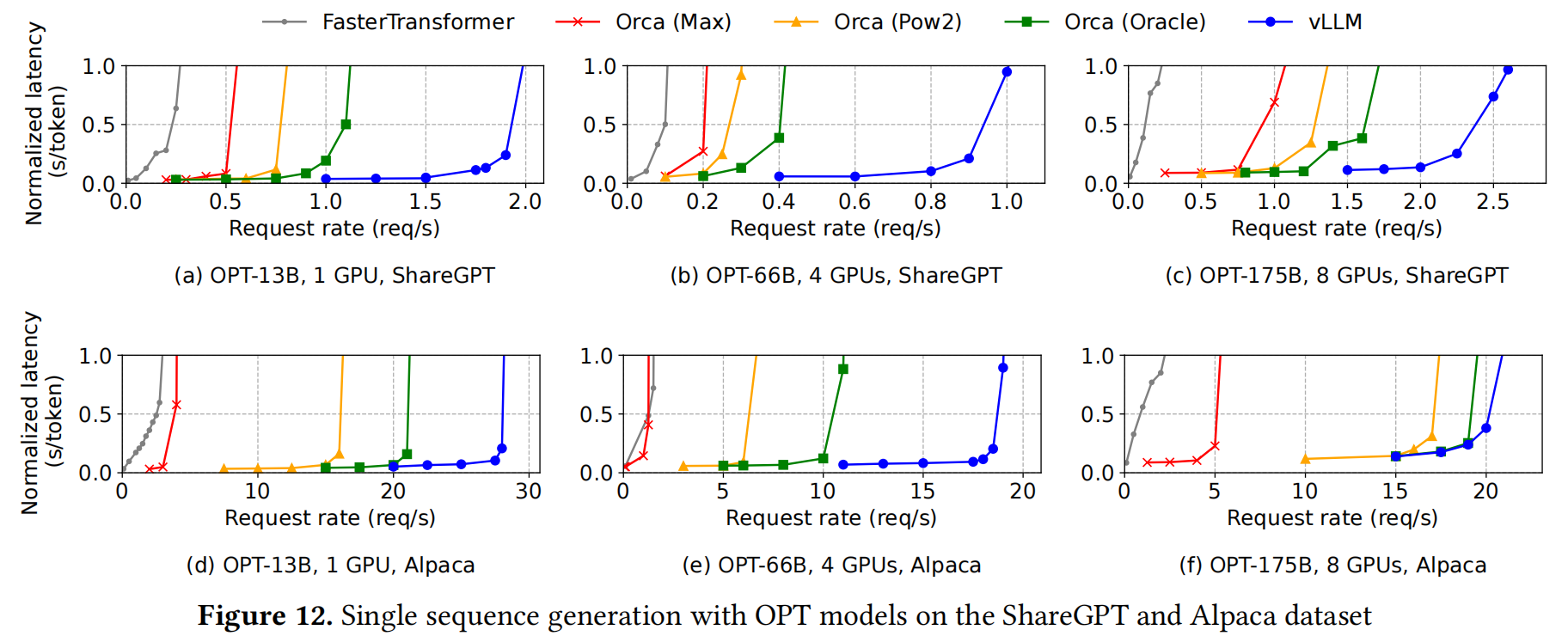
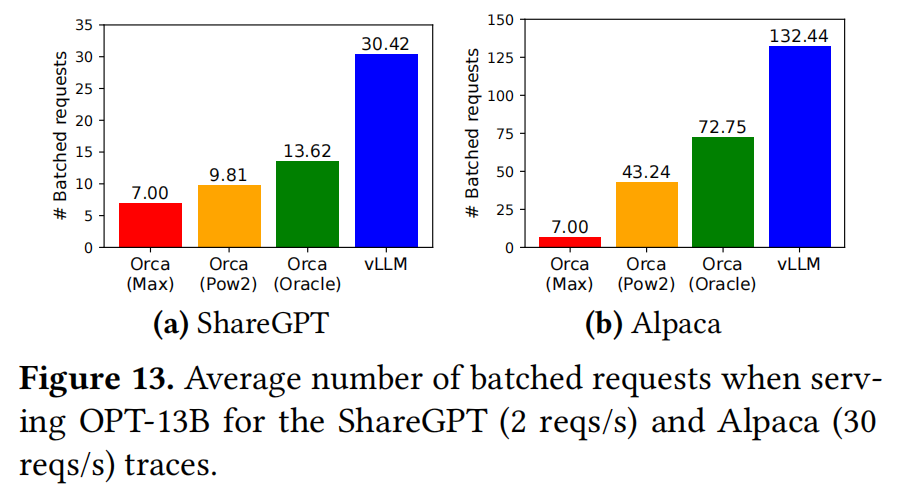
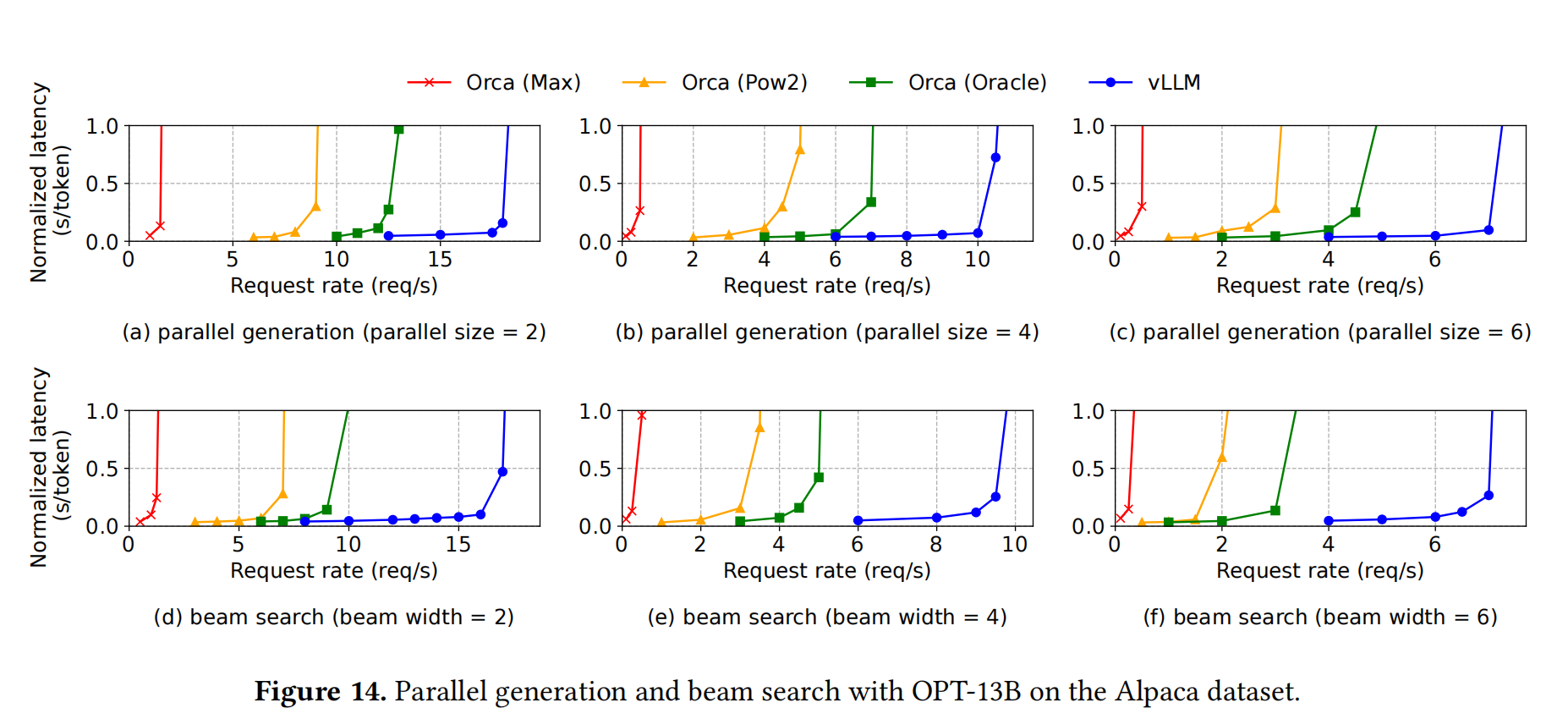
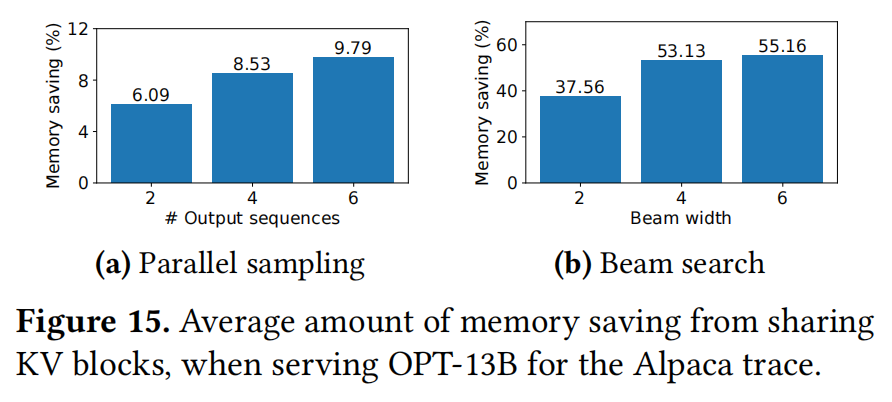
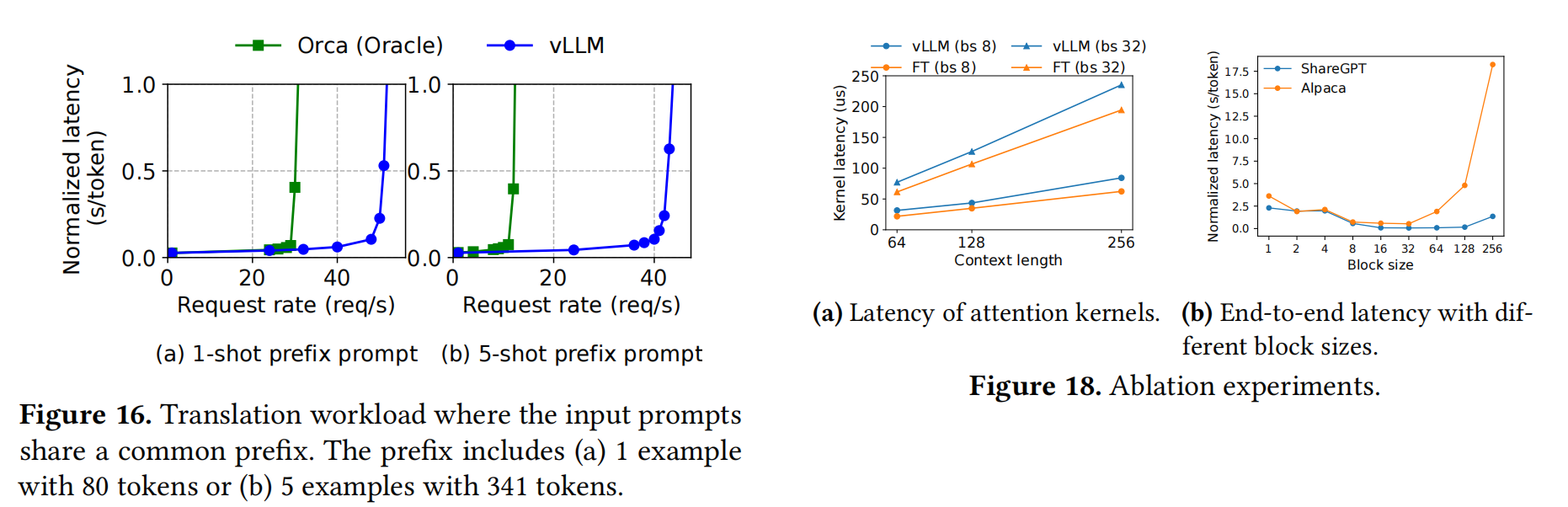
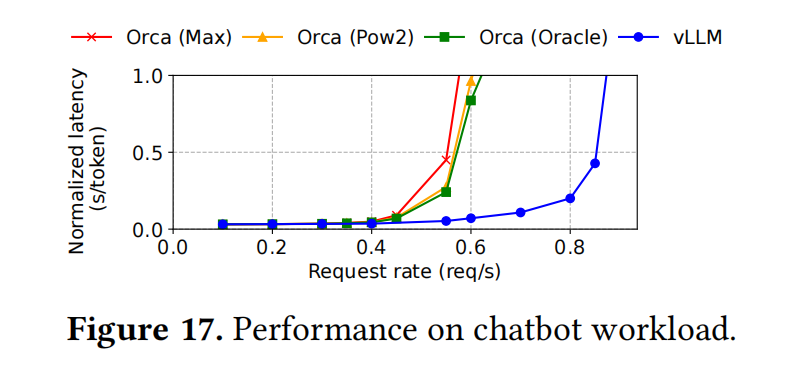
Basically, what they do is just elaborate the figrues.
In the ablation study, they found that
-
the kernal latency of PagedAttention is a little high but vLLM still way better in the end-to-end performance.
-
the best block size is typically 16.
-
the recompution and swapping is basically same when block size is from 16 to 64.
Discussion & Related Work & Conclusion
These part I think is already very concise, and also intersting, so I’ll not do the summaries.
Thoughts
In this paper, the author mentioned something called “cellular batching”. I searched a little, and it’s actually kind of similar to the Ideas(Thoughts > Ideas) I wrote in the blog for Orca.
About the Swapping and Recomputation
-
Swapping: This is just using the CPU memory, which is very common technique in current OS.
-
Recomputation: This is just throwing away all the K and V, only keeping the sequences we have already generated. We need to know that the recomputation is faster than the normal generation, since we only need one iteration to catch up. This is also very common in the current LLM training system. During the training process, we’ll get some intermediate computation results in the forward step, and these results are useful when we do the backward propagation. However, sometimes the GPU memory is not enough, so we’ll just throw away these results, and when we need them, we recompute them.
Basically, this is a way to use time for space. Actually, system work is all about suitable tradeoffs.
About the Disscussion of the Paging Technique
This is actually interesing. The PagedAttention only work for the transformer architecture, this is obvious, since if you are not transformer, you even don’t have the attention. However, it’s actually more than that, the PagedAttenion is actually only very useful for LLM, the KV cache for LLM is dynamic. If we got some ViT, I think every output size is fixed, so the KV cache should be predictable.
Still, as long as the output sequence is flexible, unpredictable. The vLLM should work well.
Also, I think vLLM is kind of like using space for time. It’s like we make for room for KV cache, the result what we see is it’s faster, since it can batch more requests at one time.
Confusion
No confusion in this paper😂.
Ideas
About copy-on write mechanism
I just thought what if we just abandon the rest, and start two new blocks. I think we can calculate some probabilities about this idea.