
Reading Notes for FasterMoE
Summary
Abstract & Introduction & Background and Challenges
前面又是简单介绍MoE,基本都一样。
这个也是training方向的,说了三个challenges:
-
dynamic load imbalance
在intro里,叫Dynamic expert selection,就也比较明显,就是每次选的experts不一样。
-
inefficient synchronous execution mode
在intro里,叫Inefficient synchronous operations,就是expert有dependency,就需要别的worker的data,要等。
-
congested all-to-all communication
在intro里,叫Mismatch of model design and network topology,感觉他的意思是现在的system只管摆放experts的computation load,不管experts之间的communication。
从abstract这里感觉他还是主要是关于解决communication方面的问题。
Intro前面又讲了很久介绍,还附了个图:
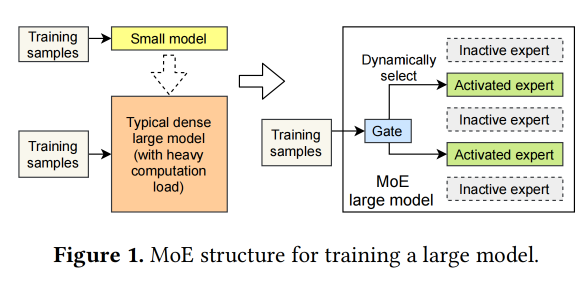
提出了一个 precise performance model,就在offline的时候根据MoE model and system configuration去预测latency。
三个方法,分别去解决上面的问题:Dynamic shadowing,A fine-grained smart scheduling strategy,a congestion-avoiding expert selection strategy。
contribution也是经典,一个a performance model,一个roofline-like model,加上上面三个方法,最合组合一起,整了一个system。六点贡献。
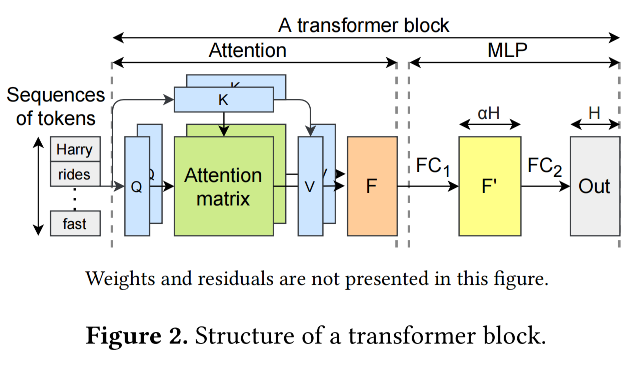
又是一个新的transformer block的结构图。
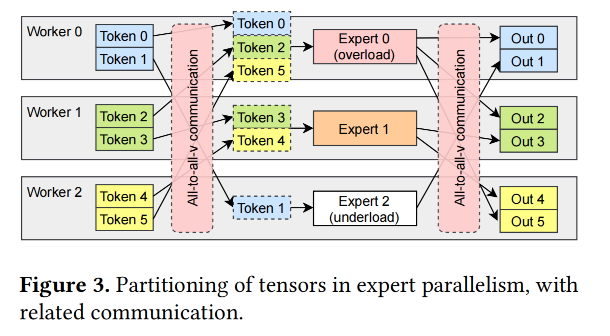
这篇论文又说可以选好几个experts,我目前还是感觉一个token只能用选一个expert,这个论文里说的可能是一个sequence里面会用不同的,有点迷惑。
再次具体的说了一下这三个challenges。
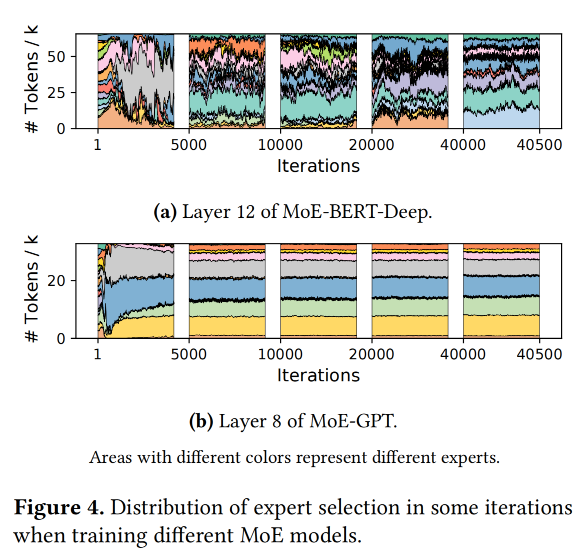
Figure 4主要说的是第一个challenge,就是分配不均衡的这个问题。
第二个就是这个communication,一般我们喜欢尽量异步,但是all-to-all communication里面有一些dependency,所以很难异步。
第三个他虽然有说一遍,但我还是没太看懂,唯一理解是这个expert assignment确实有可以优化的地方。